Eksperyment z Jirą w dużym zespole tech writerskim


Wyobraź sobie firmę programistyczną, w której 15 autorów technicznych współpracuje z setkami deweloperów i ludzi “od produktu” 😳 Jak zorganizować w Jirze pracę tak dużego zespołu tech writerów i nie oszaleć?
🧠 Atlassian Jira to narzędzie do zarządzania projektami i śledzenia zgłoszeń w zespołach programistycznych. Umożliwia planowanie, śledzenie postępów, raportowanie błędów i współpracę zespołów w oparciu o metodyki Agile.
Jakiś czas temu zaczęłam się zastanawiać nad tym, jak ulepszyć nasze procesy, ponieważ każdy z tech writerów pracował w nieco inny sposób. Dokumentację trzymaliśmy w tym samym repozytorium, owszem, ale podczas gdy część autorów korzystała z projektu dokumentacji w Jirze, niektórzy podpinali swoje zgłoszenia pod projekty deweloperów, a parę osób do zarządzania swoją pracą używała Slacka lub prywatnych notatek. Wszyscy czuliśmy, że ten sposób działania się nie sprawdza i musimy opracować coś lepszego.
Kanban na ratunek
Po zebraniu opinii od autorów i wywiadach z zespołami, z którymi współpracujemy, doszłam do wniosku, że rozwiązaniem, które warto wypróbować jest wspólny projekt dokumentacyjny i kilka tablic Kanban, które będą agregować zgłoszenia z projektów deweloperskich.
🧠 Tablica Kanban to wizualne narzędzie do zarządzania przepływem pracy, które przedstawia zgłoszenia w formie kart rozmieszczonych w kolumnach odpowiadających różnym etapom procesu, na przykład: "To do", "In progress" lub "Done".
Flirtując z filtrami tablicy
Stworzyłam więc szablon tablicy Kanban do wykorzystania i modyfikacji przez każdy z zespołów tech writerskich. Filtr, z którego skorzystałam, wyglądał mniej więcej tak:
(
project in (A, B, C, D, E, F, G, H, I)
AND (
issuetype = Document
)
)
OR
(
project in (A, B, C, D, E, F, G, H, I, J, K, L, M)
AND (
assignee was in (X, Y, Z)
OR assignee in (X, Y, Z)
OR reporter in (X, Y, Z)
)
AND NOT (
resolutiondate < -7d
AND status in (DONE, CLOSED)
)
)
ORDER BY Rank ASC
Co nam to dało? Na bazie tej przykładowej tablicy Kanban stworzyliśmy kolejnych osiem tablic (po jednej dla każdego dużego zestawu dokumentacji, który utrzymujemy). Każda z tablic powstała w tym samym Jira projekcie, dzięki czemu wszyscy uzyskaliśmy dostęp do tych samych narzędzi projektowych (na przykład automatyzacji, o czym wspomnę pewnie kiedyś w innym poście 😁 ).
To, na co warto zwrócić uwagę to fakt, że chociaż dokumentacja ma u nas osobny projekt, to większość zgłoszeń, którymi się zajmujemy, trafia do nas z projektów deweloperskich. Projekt dokumentacyjny spaja wszystko w całość i umożliwia nam zarządzanie pracą wszystkich autorów, choć każdy z zespołów pracuje często nad zupełnie innymi tematami.
Kluczowe jest przypisanie zgłoszenia autorowi. Dzięki temu zgłoszenie trafia na odpowiednią tablicę i wszyscy wiemy, kto jest odpowiedzialny za zamknięcie tematu. W zasadzie nie jest przy tym istotne, czy trafia do nas zgłoszenie typu Dokument czy coś zupełnie innego. Nie ma też znaczenia, czy jest to zgłoszenie czy zadanie podrzędne. Ważne, aby zgłoszenie zostało przypisane do autora, bo tylko dzięki temu nie zniknie nam z pola widzenia.
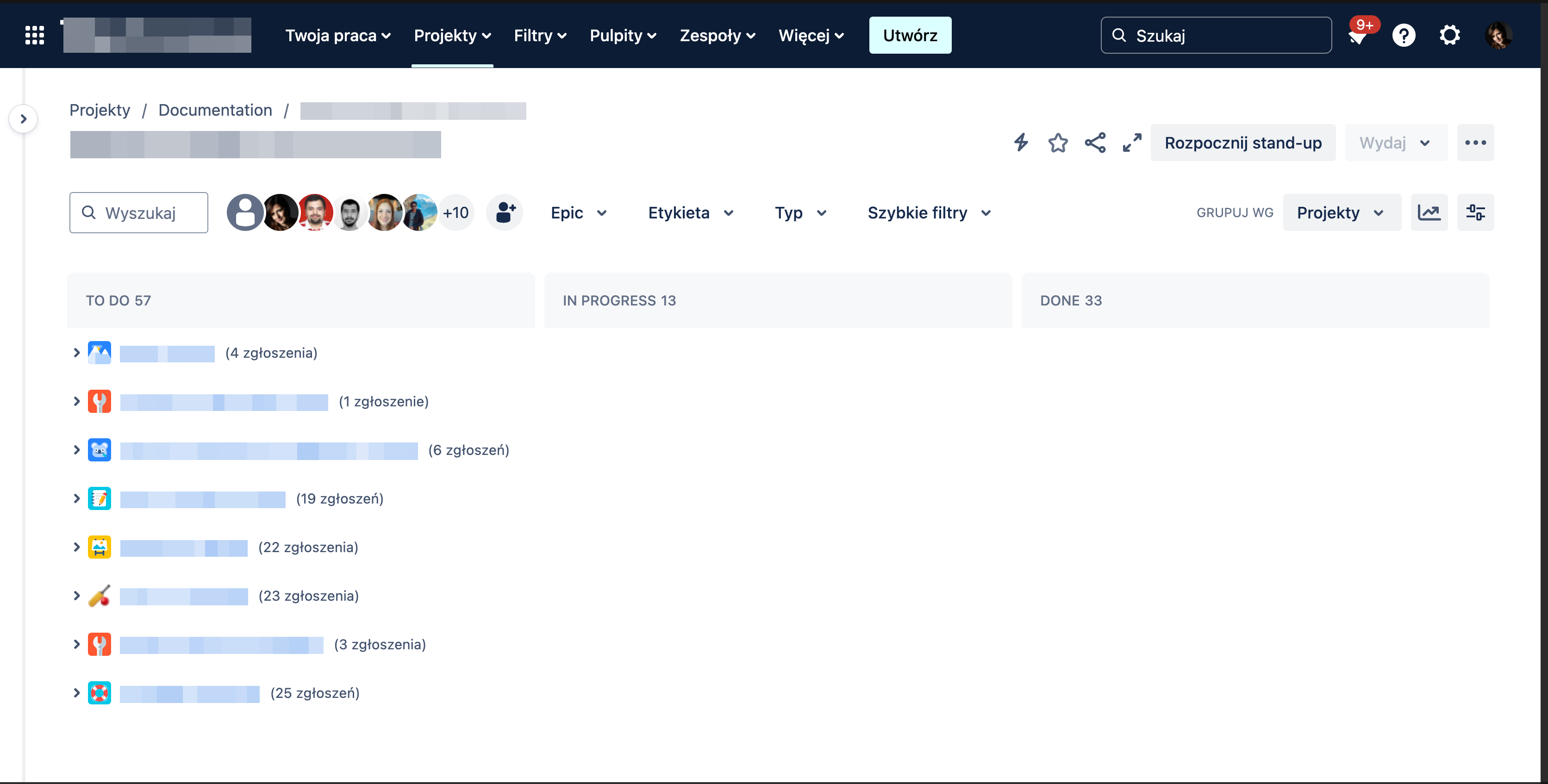
Grupowanie zgłoszeń na tablicy
Agregujemy zgłoszenia z tablic prowadzonych w innych projektach, czyli zdarza się, że status “In review” w projekcie deweloperskim u nas ląduje w kolumnie “In progress”. I to jest okej. Naszym zadaniem nie jest zmienianie procesów deweloperów, a wypracowanie sensownej strategii dla nas, z dopasowaniem się do tego, co już funkcjonuje gdzie indziej.
Dlatego uznaliśmy, że na naszej tablicy wystarczą tylko trzy kolumny: “To do”, “In progress” i “Done”. Zaskakujące, prawda? Szczególnie, kiedy patrzę na wielokolumnowe tablice programistów i zastanawiam się, co gdzie powinno trafić. Ważna jest tu komunikacja i zadbanie o to, żeby każda z osób zaangażowanych w projekt rozumiała, dlaczego zgłoszenie “In review” pokazuje się na naszej tablicy w kolumnie “In progress”.
Przydaje nam się również backlog. Nasi autorzy nie działają w sprintach. (Inaczej: właściwie to działają, ale sprinty nie wiążą nam rąk). Pomimo tego uznaliśmy, że warto prowadzić backlog. Dzięki temu łatwiej jest nam się skoncentrować na tym, czym powinniśmy się zająć w następnej kolejności, czyli kolumnie “To do”.
Na tablicy mojego zespołu zgłoszenia grupujemy w projekty, z których zgłoszenia przychodzą. Dzięki temu, kiedy dołączam do spotkania zespołu X, w zasięgu wzroku mam tylko te zgłoszenia, które realizuję dla zespołu X, a nie zgłoszenia ze wszystkich pięciu zespołów projektowych, z którymi współpracuję.
Jeden projekt za wszystkie, wszystkie do jednego
Podsumowując: proces, który udało mi się wdrożyć w zespole, świetnie się sprawdza, choć ciągle ewoluuje. Często zmieniamy filtr tablicy tak, żeby dopasować go do naszych potrzeb. Ogólna zasada jest jednak taka sama - wszyscy autorzy działają w ramach tego samego projektu w Jirze, w którym agregujemy zgłoszenia z innych projektów.
Daje nam to dużą swobodę i możliwość wykorzystania Jiry również do zadań takich jak porządkowanie dokumentacji na Confluence czy wprowadzanie zmian we wszystkich zestawach dokumentacji. Czego chcieć więcej? 😎